多线程原理
多线程(英语:multithreading),是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。具有这种能力的系统包括对称多处理机、多核心处理器以及芯片级多处理(Chip-level multithreading)或同时多线程(Simultaneous multithreading)处理器。[1] 在一个程序中,这些独立运行的程序片段叫作“线程”(Thread),利用它编程的概念就叫作“多线程处理(Multithreading)”。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程(台湾译作“执行绪”),进而提升整体处理性能。
额!!!算了算了,直接讲代码吧
多线程用法
首先导入threading库,这是python自带的库,不需要pip安装就可以使用的,最常用的有两个方法,
- 第一是threading.Thread(target=你的要调用的函数(注意:函数后面不加括号),args={x1,x2})
target后面是你用多线程跑的函数,args后面是你的函数的参数,注意了,这个里面是元组,就算是一个元素也要加逗号,这是基础了。 - 第二个是threading.Lock(),这是多线程的锁,当你不加锁的时候,你两个线程,操作同一个全局变量的话,会发生,资源竞争的情况,比如说,我定义一个全局资源num=0,现在你定义一个函数是加10000的,第二个函数也是加10000,如果不加锁的情况下,他们会竞争资源,num的值会发生错误的变化,比如变成10054,然后又变成10004,还会变小,如果加锁的情况,最终的结果是20000
多线程的运行
我在学这个的时候遇见了一个bug,就是在requests后面加了操作后,会导致最后的结果没变,也就是说,它不是从上往下依次操作的,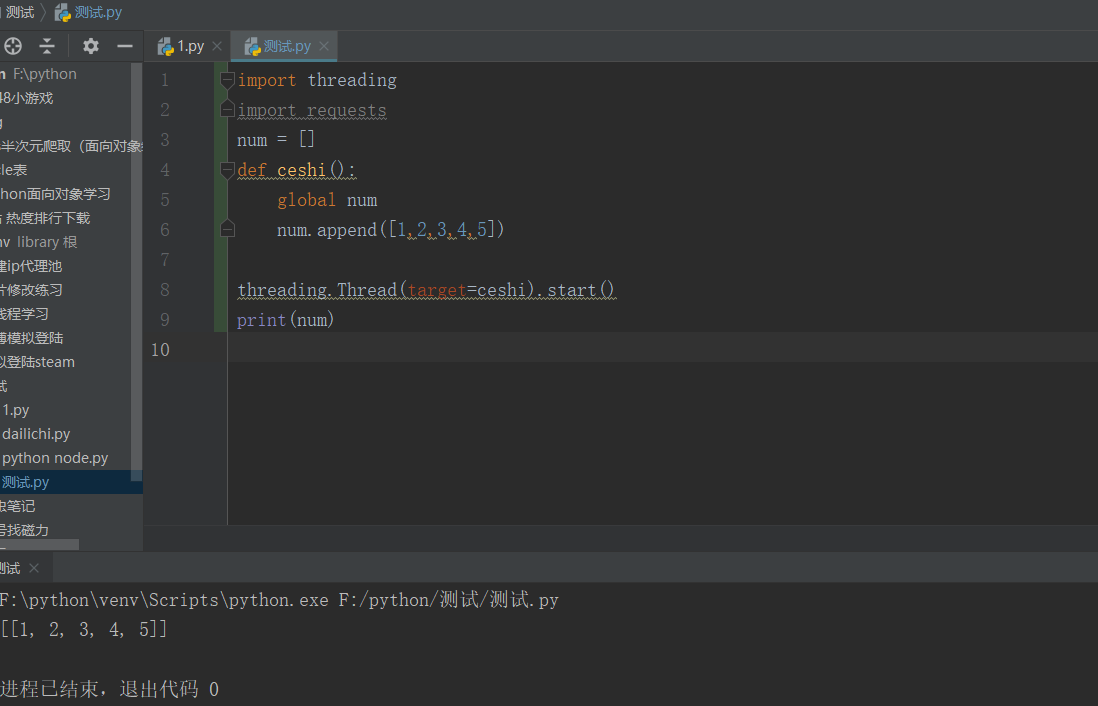
我现在加上一个requests看看哈,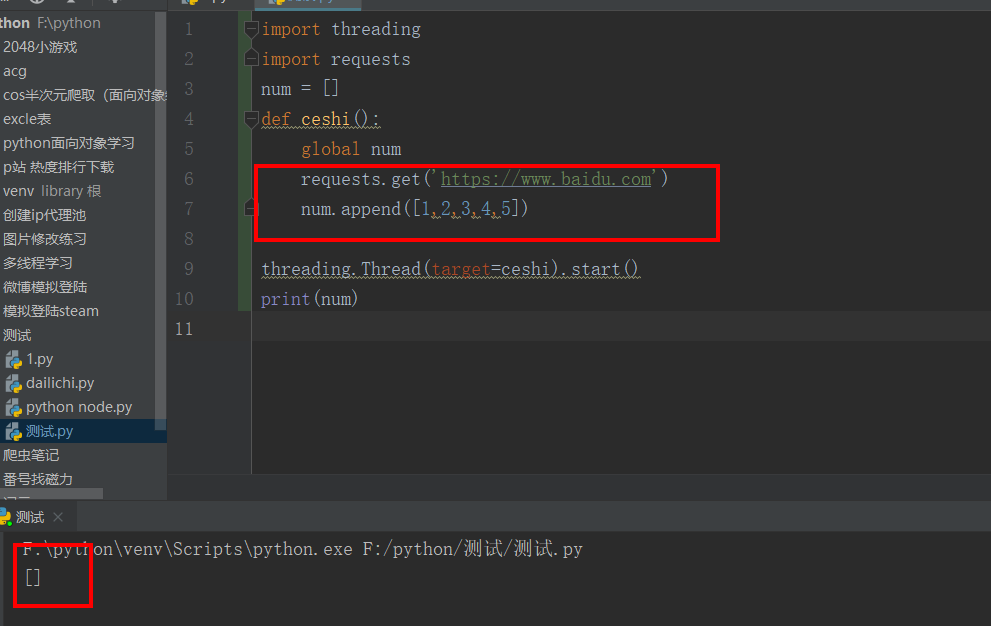
奇怪吧,那我再加一个延时,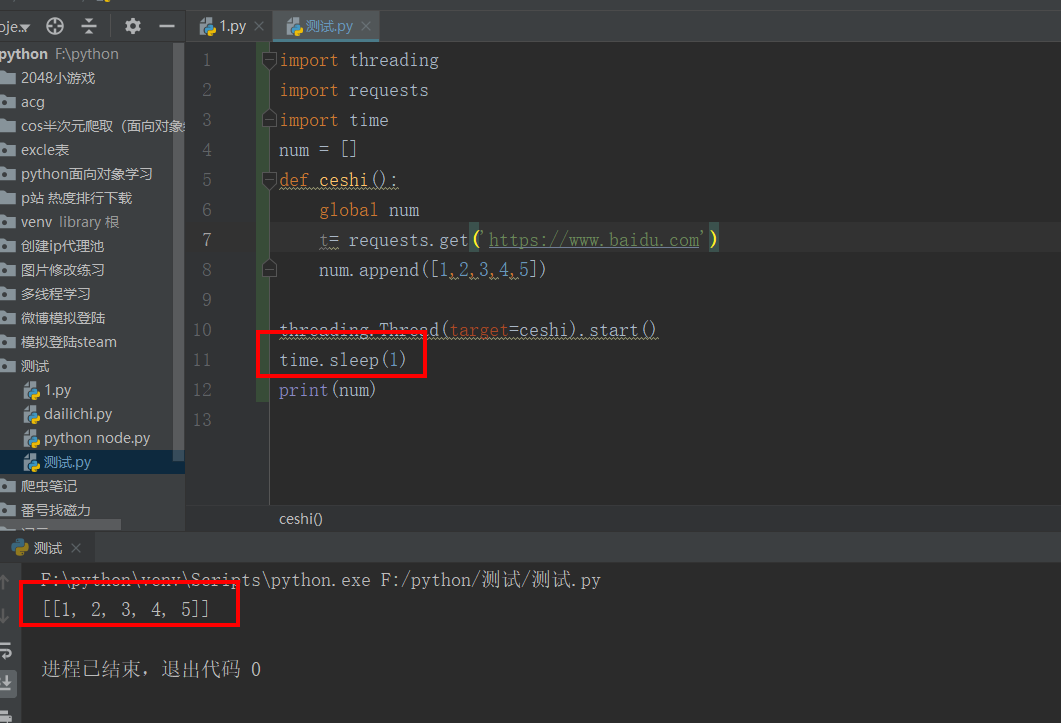
看出来什么规律没有,就是,不是从上至下,先进入了线程运行,没等它允许完,就开始进入下一个了,这就是多线程快的原因。以上,都说明了,对全局变量进行操作的时候,都是不安全的,所以要加锁,
我这里写了一个很简单的生产者消费者模型就是最简单的多线程运算了
import threading
import requests
import parsel
import os
import time
import re
import random
def dailichi():
daili = [
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; WOW64; Trident/4.0; SLCC1)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0; WOW64; Trident/4.0; SLCC1)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11'
]
dai = random.choice(daili)
# print(dai)
head ={
'User-Agent':'%s'% dai
}
return head
name = [] #这里有三个全局变量
img=[]
page_url = []
lock = threading.Lock() #这个是锁
if not os.path.exists('豆瓣'):
os.mkdir('豆瓣')
def download_img(url,name):
from urllib.request import urlretrieve
urlretrieve(url,'豆瓣'+'/'+'%s.jpg'%name)
def shengchanzhe(): #生产者,产出,它的下载链接,但是保存进一个列表里面,不下载
global img
global name
while True:
lock.acquire()
if len(page_url)==0:
lock.release()
break
url = page_url.pop()
lock.release()
response = requests.get(url,headers = dailichi())
sle = parsel.Selector(response.text)
name_title=(sle.xpath('//*[@id="content"]/div/div[1]/ol').re(r'<img width="100" alt="(.*?)" src=".*?" class="">',re.S))
for x in name_title:
name.append(x)
img_url=sle.xpath('//*[@id="content"]/div/div[1]/ol').re(r'<img width="100" alt=".*?" src="(.*?)" class="">')
for x in img_url:
img.append(x)
def xiaofeizhe(): #对上面生产者保存的列表进行逐个取值,并进行下载
while True:
lock.acquire()
if len(img)==0 and len(name)==0:
lock.release()
break
url = img.pop()
title = name.pop()
lock.release()
req = requests.get(url)
with open('豆瓣'+'/'+'%s.jpg'%title,'wb')as f:
f.write(req.content)
def page_url_get():
global page_url
for xx in range(0,246,25):
url = 'https://movie.douban.com/top250?start=%s&filter='%str(xx)
page_url.append(url)
if __name__ == '__main__':
t2 = time.time()
page_url_get()
for num in range(10): #这里是10 是线程数,可以自定义设置的
t = threading.Thread(target=shengchanzhe)
t.start()
time.sleep(1)
for num in range(10):
t= threading.Thread(target=xiaofeizhe)
t.start()
time.sleep(1)
while len(threading.enumerate())>1:
pass
t1 = time.time()
print(t1-t2)
看了这个模型应该更好理解多线程了。
这里用pop就是取出一个后就进行删除,多线程,不对多个数据进行重复操作。
哎呀,总之就是这种格式
定义一个锁
定义全局变量
定义函数:
while Trur:
上锁
if 全局变量==0:
释放锁
break
取全局变量里面的值,
释放锁
下面进行操作
for x in range(n) #n是线程数
threading.Thread(函数).start再见



